现象
1 压力测试过程中,发现被测对象性能不够理想,具体表现为:
进程的系统态CPU消耗20,用户态CPU消耗10,系统idle大约70
2 用ps -o majflt,minflt -C program命令查看,发现majflt每秒增量为0,而minflt每秒增量大于10000。
初步分析
majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
检查要访问的虚拟地址是否合法
查找/分配一个物理页
填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
此进程minflt如此之高,一秒10000多次,不得不怀疑它跟进程内核态cpu消耗大有很大关系。
分析代码
查看代码,发现是这么写的:一个请求来,用malloc分配2M内存,请求结束后free这块内存。看日志,发现分配内存语句耗时10us,平均一条请求处理耗时1000us 。 原因已找到!
虽然分配内存语句的耗时在一条处理请求中耗时比重不大,但是这条语句严重影响了性能。要解释清楚原因,需要先了解一下内存分配的原理。
内存分配的原理
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。brk是将数据段(.data)的最高地址指针_edata往高地址推,mmap是在进程的虚拟地址空间中(一般是堆和栈中间)找一块空闲的。这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
下面以一个例子来说明内存分配的原理:
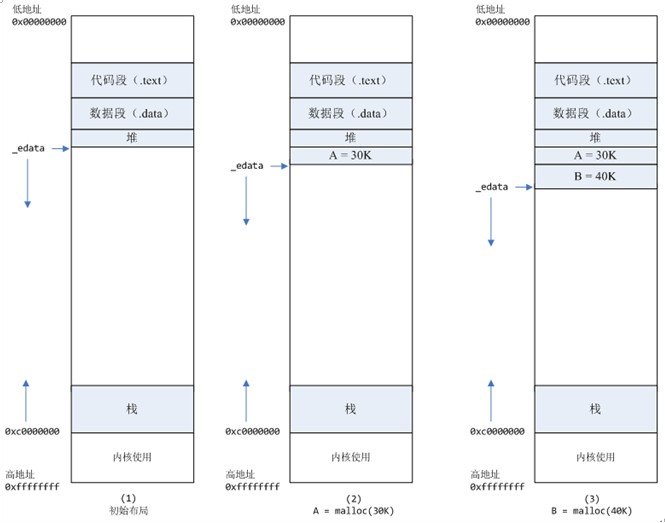
1进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。_edata指针(glibc里面定义)指向数据段的最高地址。
2进程调用A=malloc(30K)以后,内存空间如图2:malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。你可能会问:只要把_edata+30K就完成内存分配了?事实是这样的,_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3进程调用B=malloc(40K)以后,内存空间如图3.

4进程调用C=malloc(200K)以后,内存空间如图4:默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。这样子做主要是因为brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的),而mmap分配的内存可以单独释放。当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5进程调用D=malloc(100K)以后,内存空间如图5.
6进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放

7进程调用free(B)以后,如图7所示。B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8进程调用free(D)以后,如图8所示。B和D连接起来,变成一块140K的空闲内存。
9默认情况下:当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
真相大白
说完内存分配的原理,那么被测模块在内核态cpu消耗高的原因就很清楚了:每次请求来都malloc一块2M的内存,默认情况下,malloc调用mmap分配内存,请求结束的时候,调用munmap释放内存。假设每个请求需要6个物理页,那么每个请求就会产生6个缺页中断,在2000的压力下,每秒就产生了10000多次缺页中断,这些缺页中断不需要读取磁盘解决,所以叫做minflt;缺页中断在内核态执行,因此进程的内核态cpu消耗很大。缺页中断分散在整个请求的处理过程中,所以表现为分配语句耗时(10us)相对于整条请求的处理时间(1000us)比重很小。
解决办法
将动态内存改为静态分配,或者启动的时候,用malloc为每个线程分配,然后保存在threaddata里面。但是,由于这个模块的特殊性,静态分配,或者启动时候分配都不可行。另外,Linux下默认栈的大小限制是10M,如果在栈上分配几M的内存,有风险。
禁止malloc调用mmap分配内存,禁止内存紧缩。
在进程启动时候,加入以下两行代码:
mallopt(M_MMAP_MAX, 0); // 禁止malloc调用mmap分配内存
mallopt(M_TRIM_THRESHOLD, -1); // 禁止内存紧缩
效果:加入这两行代码以后,用ps命令观察,压力稳定以后,majlt和minflt都为0。进程的系统态cpu从20降到10。
小结
可以用命令ps -o majflt minflt -C program来查看进程的majflt, minflt的值,这两个值都是累加值,从进程启动开始累加。在对高性能要求的程序做压力测试的时候,我们可以多关注一下这两个值。
如果一个进程使用了mmap将很大的数据文件映射到进程的虚拟地址空间,我们需要重点关注majflt的值,因为相比minflt,majflt对于性能的损害是致命的,随机读一次磁盘的耗时数量级在几个毫秒,而minflt只有在大量的时候才会对性能产生影响。
原文出处http://blog.csdn.net/baiduforum/article/details/6126337
分享到:




相关推荐
不过直到最近优化HoLa cantk时,我才深刻的体会到内存分配对性能的影响,其中有一个关于arguments的问题挺有意思,写在这里和大家分享一下。 我要做的事情是用webgl实现canvas的2d API(这个话题本身也是挺有意思的,...
数据分析&特征平台DMP 最近频繁发生Full GC, 引发集群卡顿,导致经常超时,按照常规的方法,肯定是先看GC 日志 2020-02-17T10:17:24.672+0800: 48172.920: [GC (Allocation Failure) 2020-02-17T10:17:24.672+0800: ...
Uni-App,从了解到开发,相信大家都会觉得Uni-App性能不好,其实也这是非原生的弊病。...现在我们就从uni-app运行原理上,了解一下,在哪些方面存在性能折损问题? 逻辑层和视图层分离,非H5端通信
这个内存池主要用在需要频繁使用动态分配内存的情况下,我测试了这个内存池分配内存和malloc分配内存的效率。NedAllocator是malloc的5倍速度。而且不会存在内存泄漏。 使用方法如下: 1.拷贝文件NedAllocatorImpl.h...
内存分配的基本单位为1KB,同时要求支持至少两种分配策略,并进行测试和对不同分配策略的性能展开比较评估。 最佳适应算法(Best Fit): 它从全部空闲区中找出能满足作业要求的、且大小最小的空闲分区,这种方法...
当我们在Handler对象中使用匿名内部类或非静态内部类时,如果没有正确地释放消息,就可能会导致内存泄漏或增加Native内存。 解决这个问题的方法有两种: 减少notifyItemChanged的调用次数,尽量在数据变化后一次性...
尽管某些页交换使 Windows 2000 能够使用比实际更多的内存,也是可以接受的,但频繁的页交换将降低系统性能。减少页交换将显著提高系统响应速度。要监视内存不足的状况,请从以下的对象计数器开始: Available ...
自定义内存分配区域,减少不同的数据结构再插入和删除时需要频繁向内存区域申请空间的内存申请的动作。主要以实现单链表,队列,hash表等数据结构的频繁数据插入和删除
内存池实现内存管理; 程序中有过于频繁的内存分配及释放会有很多碎片
linux下释放经常拷贝文件导致的缓存占用[归类].pdf
摘要一个内存分配器的设计和实现摘任石弓大部分开发工具 自带的动态内存分配器或动态内存管理函数不仅运行速度慢 , 而月页面性能比较差 , 不适合用于内存频繁分配和
项目中需要用到Curl频繁调用的情况,发现curl接口调用速度缓慢。...实现高并发高性能,需要考虑资源分配和冲突的问题。 (3) 异步调用。和socket异步调用的原理类似。同步调用会阻塞等待,造成CPU占用率高。
当你在linux下频繁存取文件后,物理内存会很快被用光,当程序结束后,内存不会被正常释放,而是一直作为caching.这个问题,貌似有不少人在问,不过都没有看到有什么很好解决的办法.那么我来谈谈这个问题
由于内存的速度比CPU的速度慢得多, 在一些频繁进行 大块内存拷贝的程序中, 内存拷贝会消耗大量的时间, 从而严 重影响程序的性能。通常采用两种方法在现有CPU和内存的 条件下解决这个问题: 一是采用后台程序在CPU ...
20],我需要访问的第8个元素,首先假定第8个元素周围的元素近期将会被频繁的访问,因此在Load的数据同时将其周围的元素Load到内存中,因此需要将[8-10/2,8+10/2]这个范围的数据Load到内存中,但是[10,13]这个范围的...
在用C语言开发时,特别是在服务器端,内存的使用会成为系统性能的一个瓶颈,如频繁的分配和释放内存,会不断的增加系统的内存碎片,影响内核之后分配内存的效率,这个时候一个比较可行的做法是采用内存池,先分配好...
资源介绍:易语言的效率本来就不高而在多线程里面会频繁地申请、释放内存,因此在这里就需要一个内存池思路大概如下:申请一块大内存,分成N个单元,当用户需要的时候我们就分配一些单元给用户并标记为已用用户使用...
50种避免,发现和修复ASP.NET性能问题的方法
并且,在嵌入式系统中,由于内存的限制,频繁的动态分配不定大小的内存会引起很大的问题以及堆破碎的风险。 作为忠告,保守的使用内存分配是嵌入式环境中的第一原则。 但当你必须要使用new 和delete时,你不得...
内存虚拟硬盘 VSuite Ramdisk 提供对硬盘性能瓶颈问题的有效解决方案。它采用独特的软件算法,高效率地将内存虚拟成物理硬盘,使得对硬盘文件的数据读写转化为对内存的数据访问,极大的提高数据访问速度,从而突破...